Safe and Scalable Web Agent Learning
via Recreated Websites
VeriEnv clones diverse real-world websites — e-commerce, education, real estate, professional networking, information portals, and more — into fully executable, verifiable synthetic environments.
Abstract
Training autonomous web agents is fundamentally limited by the environments they learn from: real-world websites are unsafe to explore, hard to reset, and rarely provide verifiable feedback. We propose VeriEnv, a framework that treats language models as environment creators, automatically cloning real-world websites into fully executable, verifiable synthetic environments. By exposing controlled internal access via a Python SDK, VeriEnv enables agents to self-generate tasks with deterministic, programmatically verifiable rewards — eliminating reliance on heuristic or LLM-based judges. This design decouples agent learning from unsafe real-world interaction while enabling scalable self-evolution through environment expansion. Through experiments on web agent benchmarks, we show that agents trained with VeriEnv generalize to unseen websites, achieve site-specific mastery through self-evolving training, and benefit from scaling the number of training environments.
Why Verifiable Environments?
Existing self-evolving web agents face a fundamental tension: they learn from unsafe, unresettable real websites using unreliable LLM-as-a-judge evaluation. This feedback loop compounds errors and produces agents that overfit to the judge's biases rather than the true task. VeriEnv breaks the loop by giving agents a controlled, reproducible training ground with deterministic rewards.

| Dataset / Benchmark | # Websites | # Tasks | Browser Interaction |
Verifiable Judge |
Scalable Task Gen. |
|---|---|---|---|---|---|
| WebArena | 5 | 812 | ✓ | ✓ | ✗ |
| WorkArena | 1 | 33 | ✓ | ✓ | ✗ |
| WebVoyager | 15 | 643 | ✓ | ✗ | ✗ |
| Mind2Web | 137 | 2,350 | ✗ | ✓ | ✗ |
| Mind2Web-Online | 136 | 300 | ✓ | ✗ | ✗ |
| Mind2Web-Live | 137 | 542 | ✓ | ✗ | ✗ |
| VeriEnv (Ours) | 149 | 7,400 | ✓ w/ synthetic websites |
✓ | ✓ |
The VeriEnv Pipeline
VeriEnv automates three stages: (1) a coding agent clones the target website end-to-end (frontend, backend, and database) from screenshots; (2) bug-report passes stabilize the clone; and (3) task instructions are generated alongside executable Python SDK validation programs, so every task ships with a programmatic judge.

A verifiable task
Each generated task is paired with a ground-truth Python SDK call whose return value is the reference answer.
At evaluation time, the agent's answer is checked against this reference with deterministic operators
(exact_match, must_include, fuzzy_match, etc.).

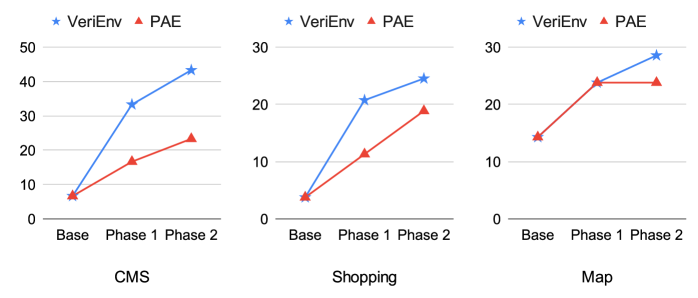
Site-specific self-evolution
Cloned Websites
VeriEnv clones websites spanning a wide range of domains — travel, commerce, education, healthcare, entertainment, government, and more. The five examples below are highlighted from our full set, with each pair showing the original website that our coding agent was given as input next to the VeriEnv clone it produced.
| Number of websites | 149 |
|---|---|
| Number of tasks per website | 49.5 |
| Total number of tasks | 7,400 |
| Easy tasks | 2,972 (40.2%) |
| Medium tasks | 2,900 (39.2%) |
| Hard tasks | 1,528 (20.6%) |
| Environment quality | |
|---|---|
| Functional correctness (avg.) | 90% |
| Signup | 94% |
| Login | 95% |
| Search | 81% |
| Filter | 88% |
| Navigation | 100% |
| Forms | 100% |
| Visual rating (Likert 1–5) | 4.7 |
| Task validity | |
| Task executability | 90% |
| Judge correctness | 76% |
Sample Generated Tasks
Tasks are generated automatically and filtered by executable validation. The selector below rotates through five representative tasks per site — a mix of information-seeking queries and authenticated multi-step actions.
Loading tasks…
Benchmark Results
Agents trained on VeriEnv-cloned environments transfer to standard web-agent benchmarks. Tables 4 and 5 show consistent gains over backbone models and prior self-evolution baselines (Synatra, ADP), evaluated on WebArena-Lite (5 real websites) and Mind2Web-Online (held-out tasks across difficulty levels). VeriEnv delivers the largest absolute improvement on both benchmarks for both backbones tested.
| Method | Shopping | CMS | GitLab | Map | Total | Δ | |
|---|---|---|---|---|---|---|---|
| Closed-source baselines | |||||||
| GPT-4o-mini† | 21.74 | 22.86 | 19.05 | 34.38 | 19.35 | 23.64 | — |
| GPT-4o† | 23.91 | 31.43 | 28.57 | 56.25 | 19.35 | 31.52 | — |
| Backbone: Qwen3-4B | |||||||
| Qwen3-4B | 3.77 | 6.67 | 4.17 | 13.89 | 14.29 | 7.88 | — |
| +Synatra | 0.00 | 0.00 | 12.50 | 8.33 | 0.00 | 3.64 | −4.24 |
| +ADP | 4.35 | 5.71 | 9.52 | 3.13 | 9.68 | 6.06 | −1.82 |
| +VeriEnv (Ours) | 4.35 | 20.00 | 23.81 | 12.50 | 16.13 | 13.94 | +6.06 |
| Backbone: LLaMA-3.2-3B-Instruct | |||||||
| LLaMA-3.2-3B-Instruct | 0.00 | 2.86 | 9.52 | 3.13 | 3.23 | 3.03 | — |
| +Synatra | 2.17 | 2.86 | 14.29 | 9.38 | 6.45 | 6.06 | +3.03 |
| +ADP | 4.35 | 11.43 | 14.29 | 12.50 | 6.45 | 9.09 | +6.06 |
| +VeriEnv (Ours) | 4.35 | 17.14 | 19.05 | 15.63 | 12.90 | 12.73 | +9.70 |
| Method | Easy | Medium | Hard | Total | Δ |
|---|---|---|---|---|---|
| Closed-source baselines | |||||
| Browser-Use-GPT-4o† | 55.40 | 26.60 | 8.10 | 30.00 | — |
| Claude-3.5-Sonnet† | 56.60 | 26.60 | 6.80 | 28.80 | — |
| Backbone: Qwen3-4B | |||||
| Qwen3-4B | 26.32 | 9.41 | 11.63 | 13.18 | — |
| +Synatra | 35.09 | 5.88 | 9.30 | 14.55 | +1.37 |
| +ADP | 26.32 | 7.06 | 6.98 | 11.36 | −1.82 |
| +VeriEnv (Ours) | 29.82 | 23.53 | 6.98 | 20.45 | +7.27 |
| Backbone: LLaMA-3.2-3B-Instruct | |||||
| LLaMA-3.2-3B-Instruct | 19.30 | 12.94 | 0.00 | 11.36 | — |
| +Synatra | 24.56 | 15.29 | 6.98 | 14.55 | +3.19 |
| +ADP | 42.11 | 24.71 | 11.63 | 24.09 | +12.73 |
| +VeriEnv (Ours) | 40.35 | 29.41 | 13.95 | 24.55 | +13.19 |
Scaling & Reliability
Increasing the number of cloned training environments consistently improves transfer to held-out websites — VeriEnv turns the cost of environment construction into a controllable axis of scale.

Compared to PAE-style LLM-as-a-judge pipelines, VeriEnv produces substantially less ambiguous tasks and more reliable evaluations.

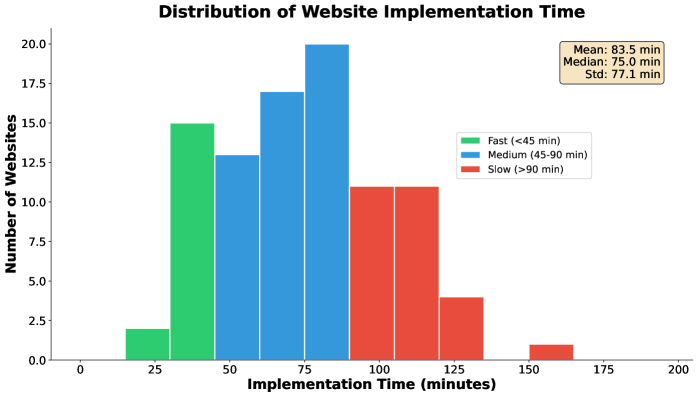
What Fails, and How Long Does It Take?

Citation
If you build on this work, please cite:
@article{chae2026verienv,
title = {Safe and Scalable Web Agent Learning via Recreated Websites},
author = {Chae, Hyungjoo and Park, Jungsoo and Ritter, Alan},
journal = {arXiv preprint arXiv:2603.10505},
year = {2026}
}